Jason Rute
Portfolio
Here are some cool things I have done.
Graph2Tac (AI for theorem proving)
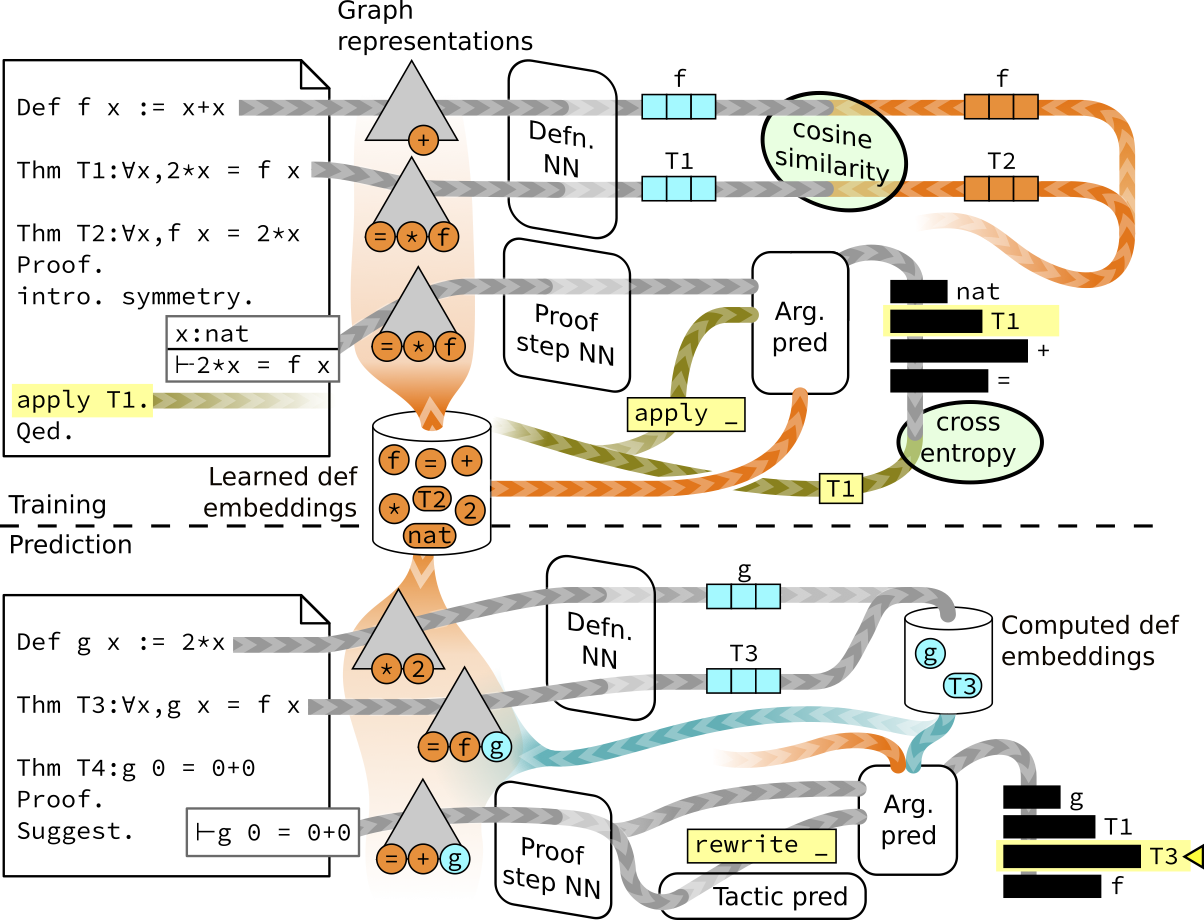
Graph2Tac is a novel neural network architecture for predicting appropriate tactics for proof states. The crucial innovation of Graph2Tac is that it can build an understanding of the math concepts in an entire Coq development and all of its dependencies on-the-fly. That is, it analyzes the structure of definitions and lemmas and builds an internal representation of each object in the global context. Then, when presented with a proof state that references these mathematical concepts, Graph2Tac can leverage its deep knowledge to predict tactics and arguments.
Lean GPT-f and Proof Artifact Co-Training (AI for theorem proving)
I along with other researchers developed an AI to prove mathematical theorems for the Lean theorem prover.
Lean is a tool to formally verify mathematical theorems down to the axioms of mathematics, providing an electronic repository of mathematics, where each proof has been certified for correctness. Developing such formal mathematical libraries are labor intensive undertakings, requiring thousands of person-hours.
This project was two-fold. First, we developed two machine learning datasets for Lean:
- jasonrute/lean_proof_recording: Proof recording for Lean 3
- jesse-michael-han/lean-step-public: Proof artifact co-training for Lean
Next, with, OpenAI, we trained a large language model on this data using a novel approach called Proof Artifact Co-Training. The resulting tool, Lean GPT-f, is a practical assistant to Lean users. In the paper Proof Artifact Co-training for Theorem Proving with Language Models we show our model is capable of proving entire theorems by itself, reproving almost 50% of the proofs in Lean’s mathlib library.
Classifying call center calls

In contract work for an outbound call center, I used supervised learning to automatically classify phone call transcripts into a half dozen industry categories (“voicemail”, “not interested”, “wrong number”, etc.) I achieved an accuracy of 84%, exceeding the companies expectations, which will free up agents from having to manually label calls.
Specifically, I started with transcripts of the phone calls generated by a third party service. I used a “bag-of-words” approach where I converted each transcript into a collection of pairs of adjacent words weighted by their uniqueness to the message. Then I trained a classifier via multiclass logistic regression with regularization. This resulted in a simple, interpretable, fast, and robust classifier which can quickly classify the phone call transcripts.
Solving Rubik’s cube via deep reinforcement learning


I used a variation of Deepmind’s AlphaZero algorithm for Go (and Chess) to learn to solve a Rubik’s cube with using no prior knowledge.
Specifically, I use a deep 3D convolutional neural network to compute a policy (next best move) and valuation (shortest number of moves to solution). This network is trained via reinforcment learning, where the algorithm uses Monte Carlo tree search to find for a solution to a randomly shuffled cube. These solutions are used, in turn, to train the next generation of the network. This new network is used to guide the next round of Monte Carlo tree search, and so on.
See here for more.
Training a neural network to play a racing game

In Coders Strike Back one programs a bot to race through an open course, touching each checkpoint in order. Using reinforcement learning I have trained a bot to be able to quickly race through the course even after being knocked around by the other bots.
Specifically, I use a small feed-forward neural network to compute a policy (next best move). This network is trained via reinforcment learning, where an optimization algorithm uses Monte Carlo search (specifically a form of evolutionary algorithm) to search for the most optimal path in randomly generated race courses. These solutions are, in turn, used to train the next generation of network. This new network is used to seed the next round of optimization, and so on.
See here for more.